Robots.txt Generator
Our robots.txt generator is a tool that helps website owners create a robots.txt file, which instructs web robots (such as search engine crawlers) how to navigate and interact with the site. The file is placed at the root of the website and can be used to allow or disallow certain robots from accessing parts of the site. Here's a basic outline of how you might set up a robots.txt generator:
Features of a Robots.txt Generator
- User Interface: A simple form where users can specify which directories or pages should be allowed or disallowed for crawling.
- Options for Bots: Allow users to specify rules for all bots or tailor rules for specific bots (e.g., Googlebot, Bingbot).
- Disallow/Allow Paths: Users can input paths they want to disallow or allow.
- Sitemap Integration: Option to add a link to the website’s sitemap.
- Syntax Checking: Ensures the syntax of the robots.txt rules is correct before saving.
- Preview and Edit: Users can preview the robots.txt file and make edits as necessary before generating the final file.
Sample Output
A typical output from a robots.txt generator might look like this:
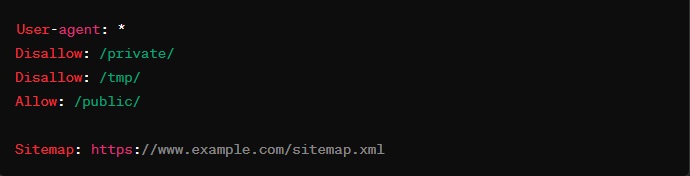
How to Use
- Enter Website Details: Input the domain and any specific bot settings.
- Set Permissions: Specify which directories are off-limits and which are open.
- Generate: The tool generates the robots.txt content based on inputs.
- Implement: The user can then copy this output and create or update the robots.txt file in their website's root directory.
This tool is beneficial for website administrators who want to control how search engines index their site, helping to prevent overloading with requests and protecting sensitive areas from being accessed.
What Is Robot.txt file in SEO?
robots.txt is a text file used by website administrators to manage and control the access of web robots or crawlers (like search engine bots) to the sections of their site. It's a crucial tool in the field of Search Engine Optimization (SEO) because it helps define which parts of a website should be crawled and indexed by search engines and which should be ignored. Here's how robots.txt plays a role in SEO:
Purpose and Functionality
- Access Control: The
robots.txt file acts as a gatekeeper for crawlers, telling them where they can and cannot go on your website. This is done by specifying directories or URLs to "allow" or "disallow".
- Resource Management: It helps conserve server resources by preventing crawlers from accessing irrelevant or resource-intensive areas of the website.
- Privacy: It can prevent search engines from indexing sensitive areas of the website, such as administrative pages, though it is not a secure method for hiding information.
Impact on SEO
- Indexing Control: Proper use of
robots.txt can improve a website's SEO by ensuring that search engines only index content relevant to the site’s objectives. This can help prevent duplicate content issues and keep the focus on high-quality, valuable pages.
- Crawl Budget Optimization: It helps optimize a website’s "crawl budget," which refers to the number of pages a search engine will crawl on your site within a given time. By disallowing certain pages, you can ensure that the crawl budget is spent on crawling important content, enhancing visibility where it matters most.
- Prevent Indexing of Non-Public Pages: By disallowing specific directories, the
robots.txt file can prevent the indexing of pages that are not meant for public viewing, such as staging sites or development areas.
Example of a robots.txt File
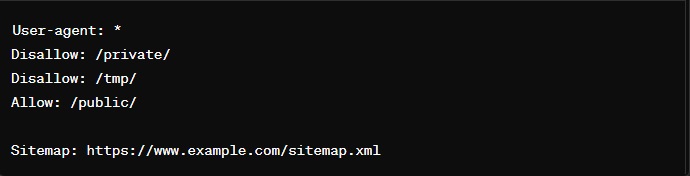
User-agent: * applies the rules to all robots.Disallow: /private/ tells robots not to access the private directory.Allow: /public/ explicitly allows access to the public directory.Sitemap: provides the URL to the site’s sitemap, aiding in more efficient crawling by search engines.
Limitations
- Security:
robots.txt is not a security measure. Disallowed paths are still accessible to anyone who directly accesses the URL; it only tells compliant robots not to crawl them.
- Not All Bots Comply: Not all bots follow the directives in a
robots.txt file, particularly malicious bots.
Basiclly, robots.txt is a tool for SEO that helps control how search engines interact with a website. It ensures that the site's bandwidth and server resources are efficiently utilized, enhancing the overall site performance and its SEO ranking potential.
The Purpose of Directives in A Robots.Txt File
The robots.txt file uses directives to communicate with web crawlers about which parts of a website they are allowed to access and index. These directives provide essential instructions to search engines and other automated bots, guiding their behavior as they navigate a site. Here's an overview of the main directives used in a robots.txt file and their purposes:
Main Directives in robots.txt
-
User-agent: This directive specifies which web crawler the following rules apply to. If you want the rules to apply to all crawlers, you use User-agent: *. You can also target specific crawlers like Googlebot or Bingbot by naming them explicitly, e.g., User-agent: Googlebot.
-
Disallow: This is used to tell a web crawler not to access certain parts of the site. Anything listed under a Disallow directive should not be crawled. For example, Disallow: /private/ instructs crawlers not to enter the /private/ directory of the website.
-
Allow: This directive is used to override the Disallow directive for more specific URLs. It's particularly useful when you have disallowed a parent directory but want to allow access to specific files or subdirectories within it. For instance, if you disallow /directory/ but want a specific file within that directory to be crawled, you can use Allow: /directory/file.html.
-
Sitemap: This directive points crawlers to the site’s XML sitemap, which lists all the URLs available for crawling. Including a sitemap helps improve the efficiency of the crawling process by ensuring that crawlers are aware of all the pages they should consider. For example, Sitemap: https://www.example.com/sitemap.xml.
Purposes of These Directives
-
Control Crawler Traffic: By using Disallow and Allow, website administrators can manage the traffic of crawlers on their servers, ensuring that server resources are not wasted on crawling unimportant or sensitive areas.
-
Improve SEO: Directives help focus the efforts of crawlers on content that is valuable for SEO. By preventing crawlers from accessing duplicate, private, or irrelevant sections of the site, the robots.txt directives help enhance the site's search engine ranking by prioritizing important content.
-
Protect Sensitive Content: While not a security feature, the Disallow directive can be used to indicate that certain areas of a site should not be indexed, such as admin pages or unpublished content, reducing the chance of their exposure in search engine results.
-
Guide Crawlers Efficiently: By pointing crawlers to the sitemap and explicitly stating which paths are accessible, robots.txt helps make the crawling process more efficient. This can lead to faster indexing of important content.
Limitations and Considerations
-
Not All Robots Comply: The directives in robots.txt rely on voluntary compliance. While reputable search engine bots will follow these rules, malicious bots might ignore them.
-
No Privacy or Security: The robots.txt file is publicly accessible. Anyone can see which parts of your site you are trying to hide from crawlers. It should not be used to secure sensitive areas.
Difference Between a Sitemap and A Robots.Txt File
Understanding the difference between a sitemap and a robots.txt file is essential for effective website management and search engine optimization. Both are tools used to communicate with search engines, but they serve distinct functions and are used in different ways.
Sitemap
A sitemap is a file that provides search engines with detailed information about all the pages and content available on a website. It is an XML file that lists URLs along with additional metadata about each URL (such as when it was last updated, how often it changes, and its importance relative to other URLs on the site). This helps search engines crawl the site more effectively and efficiently.
Key Functions of a Sitemap:
- Indexing: Helps search engines discover pages on a website, including URLs that might not be discoverable by the search engine's normal crawling process.
- Content Prioritization: Allows website administrators to provide additional information to search engines regarding the importance of specific URLs and how frequently they are updated.
- Efficiency: Aids search engines in crawling your site more efficiently by indicating which pages are more crucial and how often they might change.
Robots.txt
On the other hand, a robots.txt file is used to manage and control the behavior of web crawlers and other web robots before they visit and crawl a website. It is placed in the root directory of the website and contains directives that tell search engines which parts of the site should or should not be crawled and indexed.
Key Functions of Robots.txt:
- Access Control: Directs search engines on what parts of the site should not be accessed. This is used to prevent crawling of duplicate content, private areas, or sections that are irrelevant to external users.
- Resource Management: Helps manage the server resources by preventing crawlers from accessing heavy load or less important areas of the site.
- Guidance: Can provide the path to the sitemap, ensuring that search engines can find and use the sitemap more efficiently.
Key Differences
- Purpose: The sitemap is all about aiding discovery and ensuring that search engines are aware of all the content that the site owner considers important. In contrast,
robots.txt is about exclusion, specifying what not to crawl.
- Format: Sitemaps are usually XML files and offer a structured layout of URLs and metadata for indexing purposes.
robots.txt is a plain text file containing commands for web crawlers.
- Accessibility: While
robots.txt is accessible publicly and can be viewed by anyone who types in the website URL followed by /robots.txt, a sitemap is primarily intended for use by search engines and doesn't have to be visible or accessible to regular visitors.
By effectively using both a sitemap and a robots.txt file, website administrators can control search engine traffic on their sites and enhance their SEO by making sure search engines can access new and important content quickly while avoiding unnecessary or sensitive areas.








